Cloud-init est un logiciel appartenant à la catégorie IaaS (Infrastructure as a Service), plus précisément dans le domaine de la configuration système.
Présentation
Cloud-init est un outil Linux largement utilisé sur les plateformes cloud pour automatiser l’initialisation d’une instance lors de son démarrage. Bien qu’optimisé pour les environnements cloud, il est également compatible avec les infrastructures On-Premise.
Il permet d’exécuter diverses tâches liées à la configuration du système, telles que :
- La configuration du nom d’hôte
- La configuration des réseaux
- La gestion des utilisateurs et groupes
En plus de ces fonctionnalités, Cloud-init facilite l’installation de paquets et l’exécution de scripts, permettant ainsi d’automatiser le déploiement de logiciels dès le premier démarrage du système. Cette approche rappelle certaines tâches couramment réalisées avec Ansible.
Enfin, il est possible de configurer Cloud-init pour exécuter certaines actions uniquement au premier démarrage ou bien à chaque redémarrage de l’instance, selon les besoins.
Fonctionnement
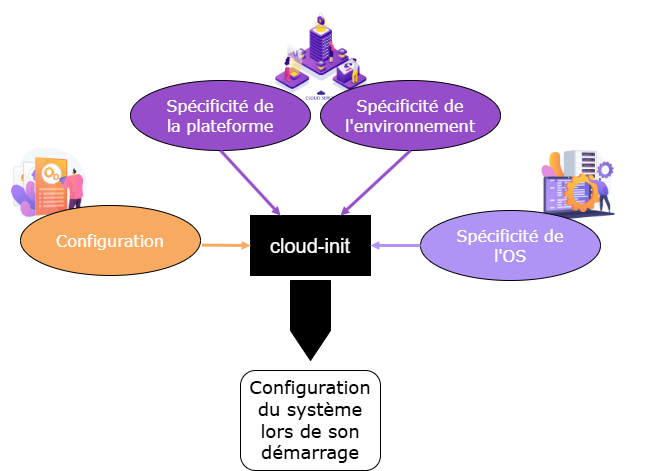
Cloud-init fonctionne comme un moteur d’initialisation automatisé qui adapte la configuration d’une instance en fonction de son environnement. Son rôle peut être résumé en plusieurs étapes :
- Détection du contexte : identification de la plateforme cloud (AWS, OpenStack, etc.) et du système d’exploitation (Debian, Red Hat, etc.).
- Récupération des métadonnées : collecte des informations spécifiques à l’environnement d’exécution.
- Application de la configuration utilisateur : prise en compte des paramètres (agnostique de l’os, de l’environnement) définis dans le fichier de configuration Cloud-init.
- Génération des fichiers système : configuration du réseau, des utilisateurs, des paramètres globaux, etc.
- Exécution de tâches complémentaires : installation de logiciels et exécution de scripts personnalisés.
En résumé, Cloud-init agit comme un pont entre une configuration générique et les spécificités de l’OS et de la plateforme. Tout ce processus se déroule automatiquement lors du démarrage de l’instance.
Phases
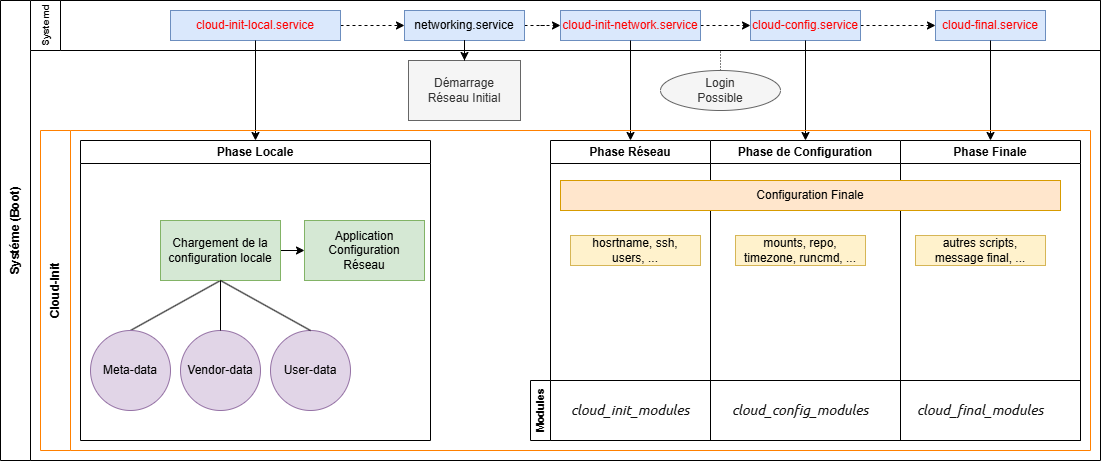
Cloud-init intervient à plusieurs étapes du démarrage du système.
- Phase locale : Dès les premiers instants du boot, avant même que le réseau ne soit complètement initialisé, Cloud-init démarre sa phase locale. À ce stade, il détecte et charge les fichiers de configuration locaux, puis applique une configuration réseau minimale.
- Phases réseau, configuration et finale : Une fois le réseau activé, Cloud-init poursuit son exécution en récupérant les ressources externes nécessaires. La configuration complète du réseau s’effectue au cours de la phase réseau, après quoi l’instance devient accessible pour la connexion.
Les différents modules exécutés au cours de ces trois dernières phases peuvent être personnalisés via le fichier de configuration de Cloud-init.
| Phase | Description | Exemple de tâches exécutées |
|---|---|---|
| Locale | Détecte la source des métadonnées et initialise les premières configurations | – Détection du fournisseur Cloud (AWS, OpenStack…) – Chargement des données locales (Disque, NoCloud…) – Configuration des logs |
| Réseau | Configure l’interface réseau avant toute autre configuration | – Attribution d’une adresse IP via DHCP – Activation des interfaces réseau – Définition du DNS, passerelle et routes |
| Configuration | Applique la configuration système de base Configure les comptes utilisateurs et SSH | – Création d’utilisateurs et SSH – Installation de packages – Configuration des dépôts |
| Finale | Exécute les actions finales après l’initialisation | – Exécution des scripts User-Data – Démarrage des services – Tâches post-configuration |
Évolution de la configuration réseau à travers les phases de Cloud-init
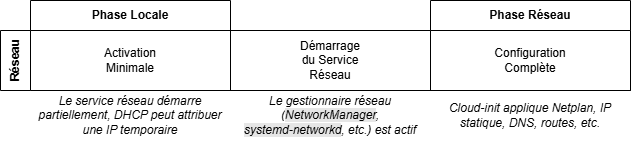
La configuration réseau progresse à mesure que Cloud-init suit ses différentes phases d’exécution.
- Phase locale : activation minimale du réseau
Lors de cette première phase, le réseau est partiellement activé, uniquement dans la mesure nécessaire pour permettre à Cloud-init d’accéder à sa source de données :- Le réseau n’est pas encore totalement configuré (pas d’IP statique, pas de DNS).
- Si la source de données est locale (CD-ROM, disque dur), aucune connexion réseau n’est requise.
- Si la source de données est externe (ex. AWS Metadata Service, OpenStack Metadata Service), une connexion minimale doit être établie.
- Si DHCP est activé, une adresse IP temporaire peut être attribuée à ce stade.
- Lors de la phase locale, le réseau est activé de manière minimale
- Phase réseau : configuration complète du réseau
C’est au cours de cette phase que Cloud-init applique la configuration réseau définitive, en s’appuyant sur des outils comme Netplan (Ubuntu) ou ifupdown.- Les paramètres réseau sont entièrement configurés : attribution d’une IP (statique ou dynamique), configuration DNS, passerelle, etc.
- Cloud-init génère les fichiers de configuration nécessaires :
- Sur Ubuntu, un fichier Netplan (
/etc/netplan/50-cloud-init.yaml) est créé, puis appliqué vianetplan apply. - Sur RHEL/CentOS, un fichier de configuration (
/etc/sysconfig/network-scripts/ifcfg-eth0) est généré et pris en charge par le service réseau. - Sur les systèmes utilisant
/etc/network/interfaces.d/, les interfaces réseau sont configurées à ce moment-là.
- Sur Ubuntu, un fichier Netplan (
- Les règles de pare-feu sont mises en place (
iptables,firewalld). - Si l’instance requiert une IP statique, elle est appliquée à cette étape.
En résumé, la phase locale permet à Cloud-init d’amorcer la connexion réseau, tandis que la phase réseau finalise la configuration complète du système.
Sources des données de configuration en phase locale
Lors de la phase locale, Cloud-init récupère ses données de configuration à partir de trois sources principales :
- Les métadonnées (Metadata)
Ces données fournissent des informations spécifiques à l’instance, comme son nom, son ID ou d’autres attributs système.- Sur une plateforme cloud, c’est l’infrastructure qui indique à Cloud-init où récupérer ces informations.
- Elles peuvent être utilisées dans les fichiers de configuration ou directement dans des scripts.
- Pour afficher l’ensemble des métadonnées disponibles, utilisez :
sudo cloud-init query --all - Ces mêmes valeurs sont également stockées dans le fichier :
/run/cloud-init/instance-data.json - Pour une description détaillée des métadonnées, consultez la section Instance-data de la documentation officielle de Cloud-init.
- Les données du fournisseur (Vendor Data)
Ces données, optionnelles, sont fournies par le cloud provider pour adapter l’instance à son environnement global.- Leur disponibilité dépend du fournisseur, par exemple:
- AWS ne fournit pas de données de ce type.
- OpenStack, en revanche, peut en fournir.
- Leur disponibilité dépend du fournisseur, par exemple:
- Les données utilisateur (User Data)
Ces données correspondent aux directives définies par l’utilisateur dans les fichiers de configuration Cloud-init.
Elles permettent d’exécuter des commandes personnalisées, d’installer des logiciels, ou encore de configurer des services spécifiques au moment du démarrage de l’instance.
Exemple de chargement des métadonnées sur AWS
Lorsqu’une instance EC2 démarre avec Cloud-init, celui-ci suit plusieurs étapes :
- Identification de la source des métadonnées : Cloud-init reconnaît qu’il s’exécute sur AWS EC2.
- Récupération des métadonnées : Une requête HTTP est envoyée à :
http://169.254.169.254/latest/meta-data - Application de la configuration système : Les données récupérées sont utilisées pour configurer le nom d’hôte, le réseau, les clés SSH, etc.
Cloud-init est donc responsable du chargement des métadonnées, en utilisant le mécanisme propre à chaque plateforme cloud.
Ici, cloud-init utilise la méthode de récupération officielle des métadonnées EC2, comme décrite par la méthode officielle : Accéder aux métadonnées d’une instance EC2.
La configuration utilisateur
La configuration utilisateur (user data) peut être définie à l’aide de trois formats principaux :
- Fichier de configuration cloud-init au format YAML.
- Script User-data, qui correspond à un script exécuté lors de la phase finale (final stage).
- Cloud boothook, un script exécuté très tôt dans le processus, durant la phase réseau (network stage).
Ces formats peuvent être combinés ou enrichis sous des formes plus complexes :
- Include file : un fichier contenant une liste d’URL pointant vers des fichiers user data. (les 3 formats sont possibles)
- Jinja template : les fichiers cloud-config et user-data scripts peuvent être écrits sous forme de templates Jinja, permettant d’utiliser toutes les variables d’instance. Cette fonctionnalité est couramment utilisée pour personnaliser les instances.
- MIME multipart file : un fichier unique contenant plusieurs formats différents.
- Cloud-config archive : similaire au fichier précédent, mais les formats sont empaquetés en YAML plutôt que via l’astuce du MIME multipart.
- Part handler : script python permettant d’ajouter ou de personnaliser les types MIME pris en charge dans un fichier MIME multipart
Descriptions de Fichiers Utilisés
/etc/cloud/cloud.cfg/etc/cloud/cloud.cfg.d/ | Configuration de cloud-init |
/var/lib/cloud/instances/<id>/user-data.txt | Données de configuration utilisateur |
/run/cloud-init/instance-data.json | Métadonnées d’instance |
/var/log/cloud-init.log/var/log/cloud-init-output.log | Logs d’exécution |
/var/lib/cloud/instance/ | Données d’état liées à l’instance |
Les fichiers dans /etc/cloud sont principalement des fichiers de configuration globale, tandis que les répertoires dans /var/lib/cloud et /run/cloud-init contiennent des informations relatives à l’exécution de cloud-init, telles que les métadonnées, les données utilisateurs. Enfin, les logs sont stockés dans le classique /var/log.
Plus d’information sur les fichiers peuvent être trouvés sur ces sources :
- répertoires et fichiers importants de cloud-init sur RedHat
- La structure du répertoire cloud-init /var/lib/cloud sur RedHat
- Disposition du répertoire sur le doc de cloud-init
Premier démarrage ?
Comme mentionné précédemment, cloud-init peut exécuter des opérations, soit uniquement au premier démarrage de la machine (opérations marquées « par instance »), soit à chaque démarrage (opérations marquées « par démarrage »).
Pour déterminer son état d’exécution, cloud-init conserve un cache qui enregistre les étapes des démarrages successifs. Si ce cache est présent, cloud-init reconnaît qu’il a déjà été exécuté sur le système. Cela peut poser problème dans deux cas :
- Un système de fichiers existant est rattaché à une nouvelle instance.
- L’instance a été créée à partir d’une image capturée d’une instance déjà initialisée.
Pour éviter ces situations, cloud-init compare également l’ID de l’instance en cours avec celui stocké dans son cache. Ce comportement, appelé « check », est activé par défaut .
Cependant, cela peut aussi poser problème si :
- L’ID de la nouvelle instance n’est pas disponible.
- Une attaque exploite ce mécanisme pour modifier l’ID d’instance stockée en cache.
Dans ces cas, le mode « trust » peut être utilisé. Il ignore la vérification de l’ID et considère le cache comme valide. Dans ce mode, la seule façon de réinitialiser l’état de l’instance est de supprimer manuellement le cache de cloud-init.
Le choix du mode utilisé se fait via le paramètre manual_cache_clean :
true → mode « trust » (cloud-init fait toujours confiance au cache).
false → mode « check » (cloud-init vérifie l’ID).
Les Modules
Comme mentionné précédemment, le travail effectué par cloud-init au cours de chaque phase repose sur différents modules. Le fichier de configuration principal définit quels modules sont utilisés à chaque étape, et il est possible de les désactiver si nécessaire.
Tous les modules disponibles sont détaillés sur la page Module de la documentation officielle.
Modules Principaux
Voici une liste des principaux modules, classés selon leur phase d’exécution par défaut :
1. Phase init (Initialisation)
Objectif : Collecter et traiter les métadonnées de l’instance
Modules principaux :
cloud-init-local: Récupère les métadonnées du fournisseur cloud et configure le réseau minimal pour la récupération.seed_random: Initialise l’entropie pour la génération de nombres aléatoires.bootcmd: Exécute des commandes au tout début du processus de démarrage.write-files: Écrit des fichiers définis dans la configuration utilisateur.set_hostname: Définit le nom d’hôte de la machine.update_hostname: Met à jour le fichier/etc/hostnameavec le nouveau nom d’hôte.update_etc_hosts: Ajoute le nom d’hôte et les adresses IP locales au fichier/etc/hosts.resizefs: Redimensionne le système de fichiers principal si nécessaire.disk_setup: Configure les partitions et formate les disques selon la configuration.mounts: Monte les partitions définies dans la configuration.
2. Phase config (Configuration système)
Objectif : Appliquer la configuration de l’instance avant que les services utilisateur ne démarrent
Modules principaux :
ssh: Configure le serveur SSH et ajoute les clés SSH.locale: Configure la langue et le jeu de caractères du système.timezone: Définit le fuseau horaire.users-groups: Crée des utilisateurs et groupes selon la configuration.ssh-import-id: Télécharge et ajoute des clés SSH depuis un service comme Launchpad ou GitHub.ca-certs: Configure les certificats d’autorité de confiance.ntp: Configure le client de synchronisation de l’heure (NTP).rsyslog: Configure le service de logsrsyslog.sysctl: Applique les réglages système spécifiques (sysctl.conf).apt-update-upgrade: Met à jour la liste des paquets (apt update) et met à niveau (apt upgrade).package-update-upgrade-install: Installe et met à jour les paquets spécifiés.snap: Installe des paquets Snap.runcmd: Exécute des commandes arbitraires définies par l’utilisateur.scripts-vendor/scripts-per-instance/scripts-user: Exécute des scripts personnalisés à différents niveaux.
3. Phase final (Finalisation)
Objectif : Effectuer les derniers ajustements et exécuter les tâches utilisateur avant que l’instance ne soit prête
Modules principaux :
phone-home: Envoie une notification à un serveur distant indiquant que l’instance est prête.scripts-user: Exécute les scripts définis par l’utilisateur (/var/lib/cloud/scripts/per-instance).scripts-once: Exécute un script unique (/var/lib/cloud/scripts/per-once).power-state-change: Arrête ou redémarre l’instance si configuré.
Autres modules
cloud-init propose plusieurs modules optionnels permettant d’intégrer des solutions de gestion de configuration telles qu’Ansible et Chef. Voici quelques-uns de ces modules :
- cc_ansible: Ce module installe Ansible lors du démarrage de l’instance et utilise
ansible-pullpour exécuter des playbooks depuis un dépôt distant. Il permet d’intégrer la gestion de configuration d’Ansible directement dans le processus d’initialisation de l’instance. - chef: Ce module installe Chef lors du démarrage de l’instance et utilise
chef-clientpour appliquer des recettes depuis un serveur Chef distant. Il facilite l’intégration de Chef dans le processus d’initialisation de l’instance - salt-minion: Ce module permet d’intégrer directement Salt Minion dans le processus de démarrage, facilitant ainsi la gestion de la configuration des instances avec SaltStack.
En intégrant ces modules, cloud-init facilite l’automatisation complète de la configuration des instances, en combinant l’initialisation de base avec des configurations plus complexes gérées par des outils spécialisés.
Il est également possible de développer ses propres modules personalisés, pour répondre à des besoins spécifiques. Ce processus est détaillé dans le chapitre Custom Modules de la documentation officielle.
Enfin dans un monde Ansible, si vous ne voulez pas déployer Ansible sur chaque machine, bref si vous voulez garder AWX comme chef d’orchestre, vous pouvez très bien également envoyer une notification à la fin de votre intialisation cloud-init afin de lancer un playbook côté AWX via un webhook.
Contexte de démarrage
Nous avons vu que les modules peuvent être exécutés soit lors du premier démarrage, soit à chaque démarrage. Voyons maintenant comment ce comportement est défini. Par défaut, voici le comportement de chaque phase :
| Phase / Section | Exécution par défault |
cloud_init_modules | 1er démarrage uniquement |
cloud_config_modules | A chaque démarrage |
cloud_final_modules | 1er démarrage uniquement |
Il est également possible de forcer l’exécution des modules à chaque démarrage en configurant le paramètre frequency sur always. Cette configuration doit être appliquée individuellement à chaque module. Voici un exemple ci-dessous :
cloud_init_modules:
- migrator
- seed_random
- bootcmd:
frequency: always
- write-files:
frequency: alwaysDans cet exemple, les modules bootcmd et write-files seront exécutés à chaque démarrage, malgrès qu’ils soient listés dans la section cloud_init_modules.
Utilisation de cloud-init
La ligne de commande
Les lignes de commande disponibles sont décrites sur le site officiel. Nous allons passer een revue ici les principales commandes de la CLI de could-init :
- Vérifier l’état de cloud-init:
cloud-init status
Cette commande affiche l’état d’éxecution de cloud-init (en cours, terminè avec succès, erreur, …) - Voir les logs de cloud-init:
cloud-init analyze show
Permet d’analayser et afficher les journaux de log pour diagnostiquer d’éventuels problèmes - Forcer une réinitialisation et redémarrer cloud init:
cloud-init clean --reboot
Supprime les anciens fichiers de configuration et redémarre la machine pour rejouer cloud-init comme si l’instance était fraîchement créée. - Voir les métadonnées appliqués:
cloud-init query userdata
Permet d’afficher les données utilisateur (user-data) fournies à l’instance. - Exécuter un module spécifique:
cloud-init single --name set_hostname
Cela exécute uniquement le moduleset_hostname, sans rejouer tout le processus. - A noter que les anciennes commandes (
cloud-init initetcloud-init modules --mode=***) permettait d’exécuter manuellement les différentes phases du processus d’initialisation. Cependant, elles sont désormais dépréciés et seront supprimées dans les prochaines versions, car leur exécution après le démarrage peut être incomplète. La seule solution fiable est de redémarrer la machine après un netoyyage aveccloud-init clean --rebootcomme vu mentionné précédemment.
Exemple de réponse sur une instance Debian sur AWS EC2
admin@host$ cloud-init status
status: done
admin@host$ cloud-init analyze show
-- Boot Record 01 --
The total time elapsed since completing an event is printed after the "@" character.
The time the event takes is printed after the "+" character.
Starting stage: init-local
|`->no cache found @00.00700s +00.00200s
|`->found local data from DataSourceEc2Local @00.03200s +00.36500s
Finished stage: (init-local) 00.88900 seconds
Starting stage: init-network
|`->restored from cache with run check: DataSourceEc2Local @02.58500s +00.01700s
|`->setting up datasource @02.64400s +00.00000s
|`->reading and applying user-data @02.64800s +00.00200s
|`->reading and applying vendor-data @02.65000s +00.00000s
|`->reading and applying vendor-data2 @02.65000s +00.00000s
|`->activating datasource @02.66600s +00.00000s
|`->config-migrator ran successfully @02.70200s +00.00100s
|`->config-seed_random ran successfully @02.70300s +00.00000s
|`->config-growpart ran successfully @02.70300s +00.07700s
|`->config-resizefs ran successfully @02.78100s +00.00700s
|`->config-mounts ran successfully @02.78800s +00.00100s
|`->config-set_hostname ran successfully @02.78900s +00.00100s
|`->config-update_hostname ran successfully @02.79000s +00.00000s
|`->config-users-groups ran successfully @02.79000s +00.13300s
|`->config-ssh ran successfully @02.92300s +00.62000s
Finished stage: (init-network) 00.97000 seconds
Starting stage: modules-config
|`->config-ssh-import-id ran successfully @04.14100s +00.00000s
|`->config-locale ran successfully @04.14100s +00.00100s
|`->config-set-passwords ran successfully @04.14200s +00.01200s
|`->config-grub-dpkg ran successfully @04.15400s +00.26400s
|`->config-apt-configure ran successfully @04.41800s +00.03900s
|`->config-byobu ran successfully @04.45700s +00.00100s
Finished stage: (modules-config) 00.35300 seconds
Starting stage: modules-final
|`->config-reset_rmc ran successfully @04.84300s +00.00200s
|`->config-refresh_rmc_and_interface ran successfully @04.84500s +00.00100s
|`->config-rightscale_userdata ran successfully @04.84600s +00.00000s
|`->config-scripts-vendor ran successfully @04.84700s +00.00000s
|`->config-scripts-per-once ran successfully @04.84700s +00.00100s
|`->config-scripts-per-boot ran successfully @04.84800s +00.00000s
|`->config-scripts-per-instance ran successfully @04.84800s +00.00000s
|`->config-scripts-user ran successfully @04.84800s +00.00000s
|`->config-ssh-authkey-fingerprints ran successfully @04.84900s +00.01000s
|`->config-keys-to-console ran successfully @04.85900s +00.05600s
|`->config-install-hotplug ran successfully @04.91500s +00.00100s
|`->config-final-message ran successfully @04.91600s +00.00600s
Finished stage: (modules-final) 00.13500 seconds
Total Time: 2.34700 seconds
1 boot records analyzed
admin@host$ cloud-init single --name set_hostname
Cloud-init v. 22.4.2 running 'single' at Sat, 01 Feb 2025 10:03:56 +0000. Up 227092.61 seconds.Fichier de configuration
Voici un example de fichier de configuration cloud-config.yml:
#cloud-config
users:
- name: admin
sudo: ALL=(ALL) NOPASSWD:ALL
groups: sudo
ssh-authorized-keys:
- ssh-rsa AAAAB3...
package_update: true
package_upgrade: true
packages:
- nginx
runcmd:
- systemctl start nginxAu premier démarrage, ce fichier permet:
- De créer un utilisateur
adminavec droits sudo et avec accès SSH (la clé publique est fournie) - De mettre à jour le système à son démarrage, via l’utilisation de
package_updateetpackage_upgrade - D’installer
nginx - De démarrer
nginxaprès l’installation (cette commande étant dans la sectionruncmd, elle sera effectué à chaque démarrage)
Idempotence
Retour sur l’exemple du module users-groups
On m’aurait menti ??? Nous venons bien de dire que le user admin allait être crée au 1er démarrage. Hors le module users-groups fait parti de la phase config de cloud-init, qui s’exécute donc techniquement à chaque démarrage. Mais cela ne signifie pas qu’il recrée ou modifie les utilisateurs à chaque reboot. Explication:
- Le module
users-groupss’exécute bien à chaque démarrage, mais…cloud-initvérifie si l’utilisateur existe déjà avant d’appliquer la configuration.- Si l’utilisateur existe déjà, il n’est pas modifié (ni supprimé, ni recréé).
- Si l’utilisateur n’existe pas, il est créé avec la configuration définie
- Que se passe-t-il à chaque démarrage ?
- À chaque boot,
cloud-initrejoue bien les modules de la phaseconfig, y comprisusers-groups, mais : - Si l’utilisateur est déjà présent dans
/etc/passwd→ rien ne change. - Si un utilisateur est supprimé manuellement → il sera recréé
- À chaque boot,
- Conséquence :
cloud-initne « force » pas la modification des utilisateurs existants.- Il ne « remplace » pas les clés SSH ou les permissions si elles ont changé.
- Il ajoute les utilisateurs qui manquent.
Idempotence et cloud-init : Pas systématique !
En principe, un module est idempotent si :
- Il peut être exécuté plusieurs fois sans effet secondaire.
- Il ne refait pas une action inutilement si elle est déjà appliquée.
Mais dans cloud-init, ce n’est pas toujours le cas ! Certains modules vérifient l’état actuel avant d’agir (idempotents), d’autres non (non idempotents). Mais on trouve souvent une idempotence partiel : par exemple, si une configuration existe déjà, elle ne sera pas recréée, mais son contenu ne sera pas vérifié ni mis à jour.
Voici un tableau pour mieux comprendre le comportement de cerains modules:
| Module Phase config | Idempotance | Explication |
users-groups | ❌ Non | Ne modifie pas les utilisateurs existants mais recrée ceux supprimés |
ssh | ❌ Non | Ne recrée pas les clés SSH si elles existent déjà, mais ne met pas à jour une clé SSH existante, même si elle a été modifiée. |
write-files | ✅ Oui | Écrit le fichier seulement si son contenu change. |
package-update | ❌ Non | Ne s’exécute qu’une seule fois au premier boot |
runcmd | ❌ Non | Exécuté une seule fois (sauf si relancé manuellement) |
bootcmd | ✅ ❌ | Exécuté à chaque démarrage avant tout autre processus. L’idempotence dépend des scripts inclus. |
mounts | ❌ Non | Ne refait pas un montage s’il existe déjà mais ne met pas à jour les options d’un montage existant si elles sont différentes de la configuration. |
apt-configure | ❌ Non | Ne modifie que si la config change, mais ne garantit pas une idempotence complète pour la configuration APT. |
locale | ✅ Oui | Ne rechange pas la locale si elle est déjà correcte |
Examples de configuration
De nombreux examples de configuration sont disponibles sur le site officielle: All cloud config examples. Cetains configurations sont également plus détaillés, comme la cas de la configuration du réseau, sur cette page Networking config Version 1 ou cette autre page Networking config Version 2.
Validation et Tests des configurations
Validation du Schéma
Vous pouvez valider un fichier de configuration avant de l’utiliser en exécutant la commande suivante :
$ cloud-init schema --config-file cloud-config.yamlSi le fichier est valide, le message suivant s’affichera :
Valid schema cloud-config.yamlDans le cas contraire, des informations détaillées vous seront fournies pour vous aider à identifier et corriger les erreurs présentes dans le fichier.
Test des configurations
Avant de déployer votre configuration sur des instances réelles, il est judicieux de la tester localement:
- Avec QEMU vous pouvez créer une image de machine virtuelle, y intégrer votre configuration coud-init et la lancer avec QEMU pour observer le comportement
- Multipass peut également être utilisé pour tester des configuration cloud-init, bien que prévu initiallement pour lancer des machines virtuelles Ubuntu en local.
- Sur des conteneurs LXD: LXD a un support natif de cloud-init, il permet donc de facilier le processus de test et d’itération sur vos scritps de configuration. L’utilisation de LXD apporte certains avantages:
- Support natif de
cloud-init: De nombreuses images disponibles dans LXD incluent déjàcloud-init, ce qui simplifie la configuration initiale. - Rapidité et légèreté : Les conteneurs LXD sont généralement plus légers et démarrent plus rapidement que les machines virtuelles traditionnelles, ce qui accélère les cycles de test.
- Support natif de
- Le test est également possible sur VMs ou conteneurs avec Incus. Ce dernier prend en charge cloud-init, ce qui permet de personaliser et d’automatiser l’initialisation des instances que ce soit des conteneurs ou des machines virtuelles.
Les options QEMU, LXD et Multipass sont documentés sur la documetation officielle: How to test cloud-init locally before deploying. Des tutoriaux seront également mis en place dans le futur sur ce blog. Les liens seront ajoutés ici, le cas échéant.
Limitation des tests si l’environnement visé est dans le cloud:
Tester des configurations cloud-init qui dépendent des métadonnées spécifiques comme celles d’AWS EC2 peut être complexe en environnement local, car cela nécessite l’émulation du service de métadonnées d’EC2. Cependant, il existe des approches pour simuler cet environnement :
- Utilisation de simulateurs de métadonnées EC2 :Des outils comme
ec2-metadata-mockpeuvent être utilisés pour émuler le service de métadonnées EC2 en local. Cela permet àcloud-initde récupérer les métadonnées comme si l’instance s’exécutait sur AWS. - Tests dans un environnement AWS réel :Pour des tests plus précis, il est recommandé de déployer vos configurations
cloud-initdirectement sur des instances EC2. Vous pouvez utiliser des instances de type t2.micro ou t3.micro, qui sont éligibles à l’offre gratuite d’AWS, pour effectuer vos tests sans coûts significatifs. - Utilisation de Multipass :Bien que des outils comme Multipass soient principalement conçus pour lancer des machines virtuelles Ubuntu en local, ils peuvent être utilisés pour tester des configurations
cloud-init. Cependant, cette approche peut ne pas couvrir toutes les spécificités des métadonnées AWS EC2.
En résumé, bien qu’il soit possible de simuler les métadonnées EC2 en local, la méthode la plus fiable pour tester des configurations cloud-init dépendantes des métadonnées AWS est de les déployer directement sur des instances EC2.